|
•
|
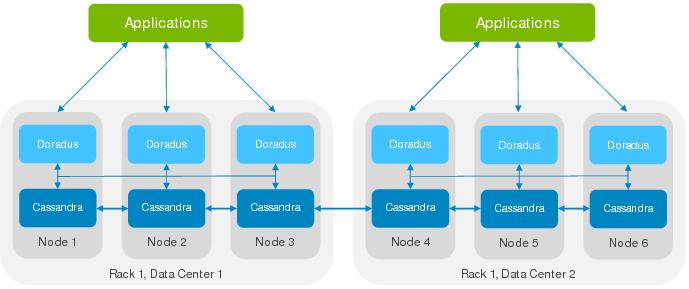
Application: One or more client applications perform schema changes, update objects, and submit queries using the Doradus REST API when Doradus executes as a standalone process. However, applications can also embed Doradus in the same JVM and call internal services directly.
|
|
•
|
Monitor Application: Doradus uses the JMX API to monitor server resource usage. A JMX application such as JConsole can be used to invoke JMX functions.
|
|
•
|
Doradus Server: This is the core Doradus component, which processes commands and maps requests to Cassandra using either the Thrift API or CQL API. The doradus.yaml file is the primary Doradus configuration file.
|
|
•
|
Cassandra Server: This is the core Cassandra server, which provides persistence, replication, elasticity, and other database services. Cassandra’s primary configuration comes from the cassandra.yaml file. Cassandra stores data in various data and log files.
|
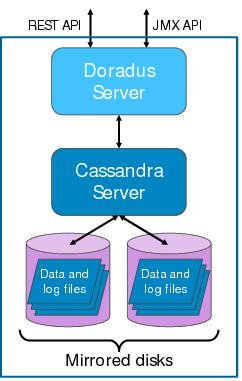
When multiple Doradus instances are used in the same cluster, they are peers: any request can be sent to any instance. If a node fails, applications can redirect requests to any available instance. Doradus instances also communicate with each other to distribute background worker tasks and coordinate schema changes.
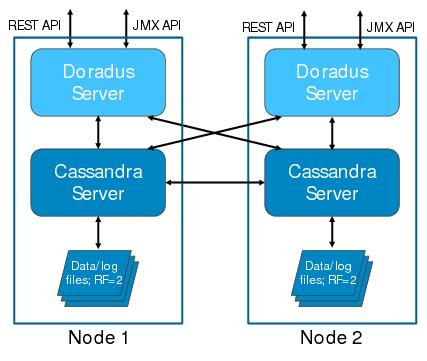
Cassandra also supports multi-data center deployments. Each Cassandra node is configured with a specific rack and data center assignment. A rack is usually network-near to other racks in the same data center but independently powered. Data centers are geographically dispersed. With rack and data center awareness, Cassandra can use a replication policy that ensures maximum availability should a node, rack, or entire data center fail. An example of a multi-rack/multi-data center deployment is shown below, using the same model of deploying a Doradus instance on each node: